LOG-NORMAL STATE PREPARATION
Background:
Many quantum algorithms rely on initializing qubits in a specific state. The promised speedup of the algorithm depends on the ability to prepare the quantum state efficiently. The challenge of preparing a quantum state is an example of a broader use case of compiling isometrics into specific quantum circuit and it is known that, in general, an exponential number of gates, O(2n), are needed.
One of the popular distributions is the log-normal distribution, used in many places such as in the Black-Scholes model option pricing formula. The log-normal distribution is given by:
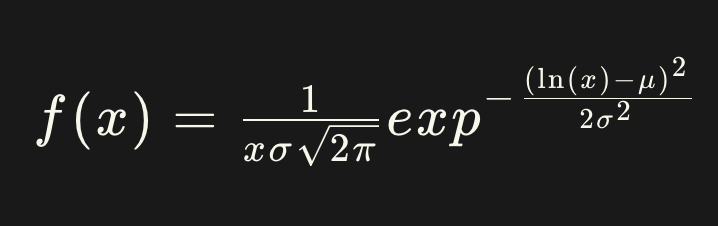
Problem:
The challenge for the Classiq Coding Competition was preparing a log-normal distribution with μ = 0 and σ = 0.1, using single-qubit rotation ‘u’ and ‘CX’ gates, and with the target distribution error < 10−2 , where the metric is the L2 norm and values outside the state-vector domain are assumed to be zero.
Competitors were allowed up to 10 qubits, split between state and auxiliary qubits as they saw fit, and any mapping between the state vector domain D to the distribution domain (i.e. the discretization) as long as it was continuous.
Winning Metric:
The winners were chosen based on the shortest depth state-preparation. As many competitors had circuit depths of one with varying distribution domains, winners were chosen based on time of submissions.
Out of the box?
Solving this problem required a little bit of out-of-the-box thinking to win. There were two main degrees of freedom: the discretization and the actual state preparation algorithm. Some competitors assumed uniform discretization, generated non-equal values for the function in each discretization bin, and thus caused more work on the state preparation side. However, with the right discretization, the circuit is trivially simple and has a depth of one.
FIRST PLACE - Yotam Vaknin, Israel
Yotam implemented a 10 qubit, log-normal state preparation using a uniform distribution over all bit strings (i.e. a single layer circuit) and selecting of the section with very minimal precision using the CDF of the log-normal distribution.
For a Jupyter Notebook of the first place Log-Normal State Preparation, see here.
SECOND PLACE - Konrad Deka, Poland
Konrad used the natural discretization given by dividing the codomain of cumulative distribution function into even parts. For the quantum state, he used 10 qubits: the circuit simply consists of a Hadamard gate on each qubit. The l2_error function given in the example in the problem statement gives the value 0.00547, which is below the required 0.01 threshold.
For a Python file of the second place decomposition, see here.
THIRD PLACE - Tristan Nemoz, France
Tristan analyzed the way the error was defined to know the optimal probability on a given interval to minimize it. He chose the discretization so that he could set all the probabilities to 1/2^n. Tristan prepared a log-normal state using 10 qubits with circuit depth 1.
For a Jupyter Notebook of the third place decomposition, see here.
FOURTH PLACE - Jan Tułowiecki, Poland
With only 9 qubits, Jan created a log-normal state preparation within the error bound. Though circuit depth was the winning metric, followed by time of entry, we must reward this incredible submission with an honorable mention.
For a full, and very in-depth, explanation of the fourth place Log-Normal State Preparation, see here.